





Trymata’s latest product update is an improvement to our recently released moderated testing suite. Now, when you get transcripts for your moderated user test recordings, the speech of the moderator and the participant will be automatically separated and labeled.
With this update, it will be even easier to go back and review your test videos, and find key pieces of the conversation.
How it works
Here’s everything you need to know about these improvements – with screenshots.
Automatically splitting the transcripts by speaker
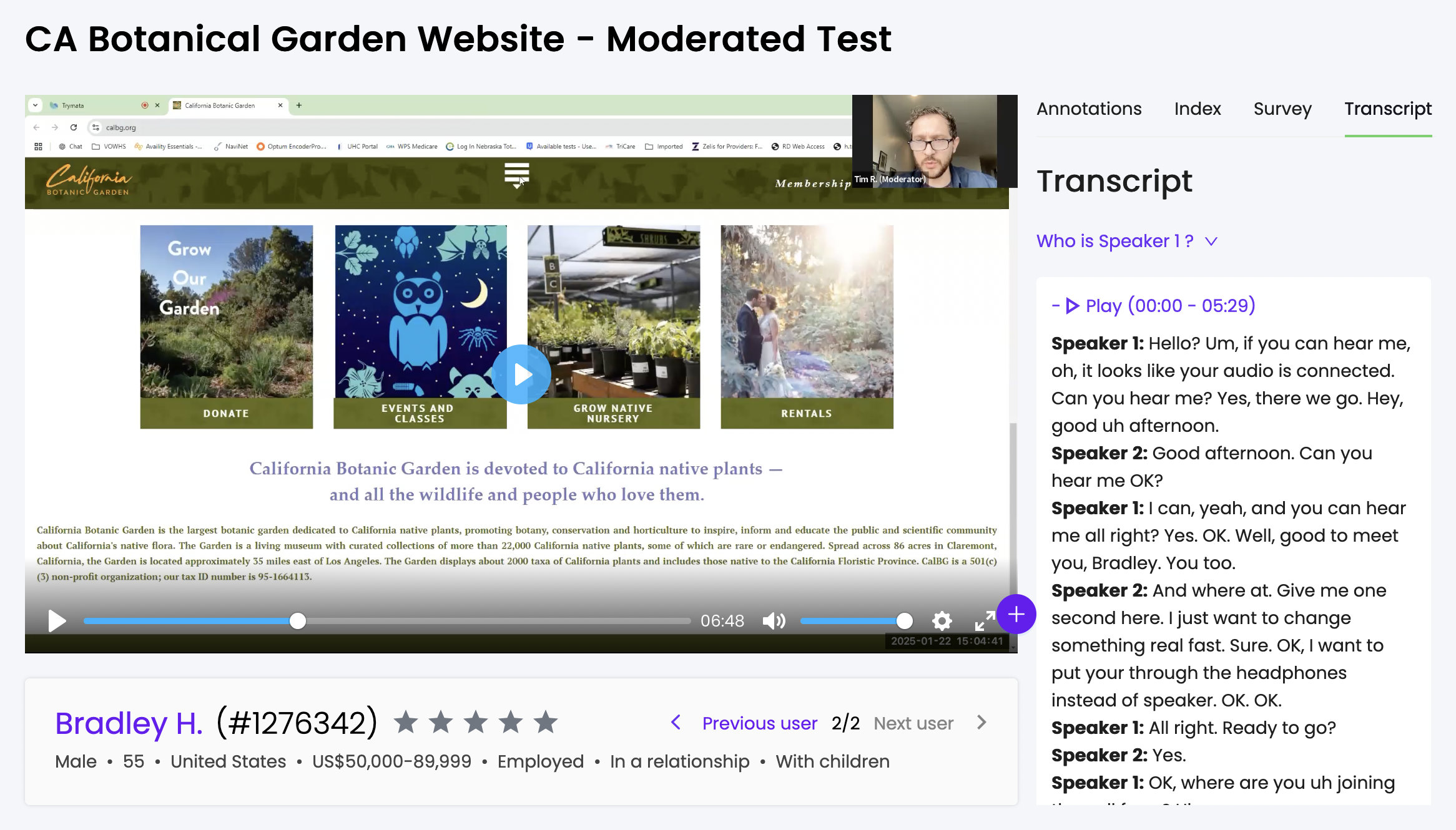
When you generate transcripts for your moderated test videos, the Trymata software will not only transcribe all of the speech in your video files – it will also automatically detect which words were spoken by the same participant.
Based on the unique sonic qualities of each person’s voice, the transcription software can identify the 2 different speakers present in the moderated call. This means that every time the active speaker changes, we can automatically flag it, and label it.
Then, when your transcripts come in, you’ll see all of the text already split between a “Speaker 1” and a “Speaker 2.”
Easily assign names to each speaker
When you first view the transcript for your moderated test video, the speaker labels will not yet be assigned by name. However, we’ve built in a fast and easy way to match up the identified speakers with the people in the call.
At the top of your transcript view, you’ll see a clickable piece of text that reads: “Who is Speaker 1?”
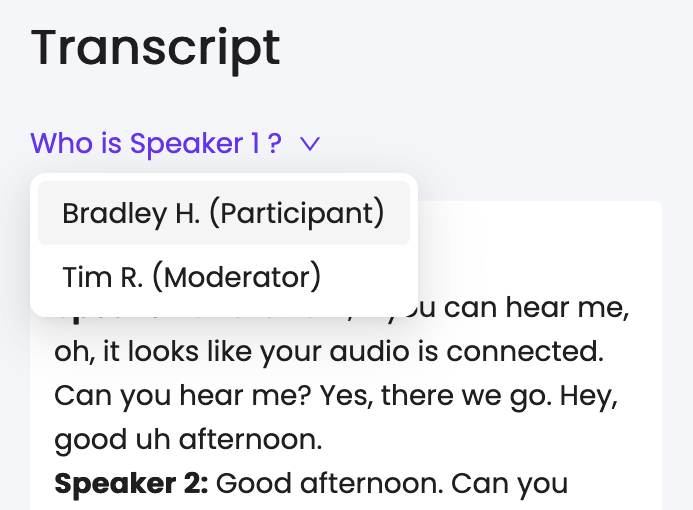
When you click on it, Trymata will open a dropdown auto-filled with the names (and roles) of the moderator and the tester for that session. Simply pick from the dropdown which person is the speaker of the lines labeled “Speaker 1,” and their name will be instantly swapped in for those lines throughout the transcript.
Since moderated sessions only have 2 speaking participants, Speaker 2 will also instantly be swapped out for the other remaining name.
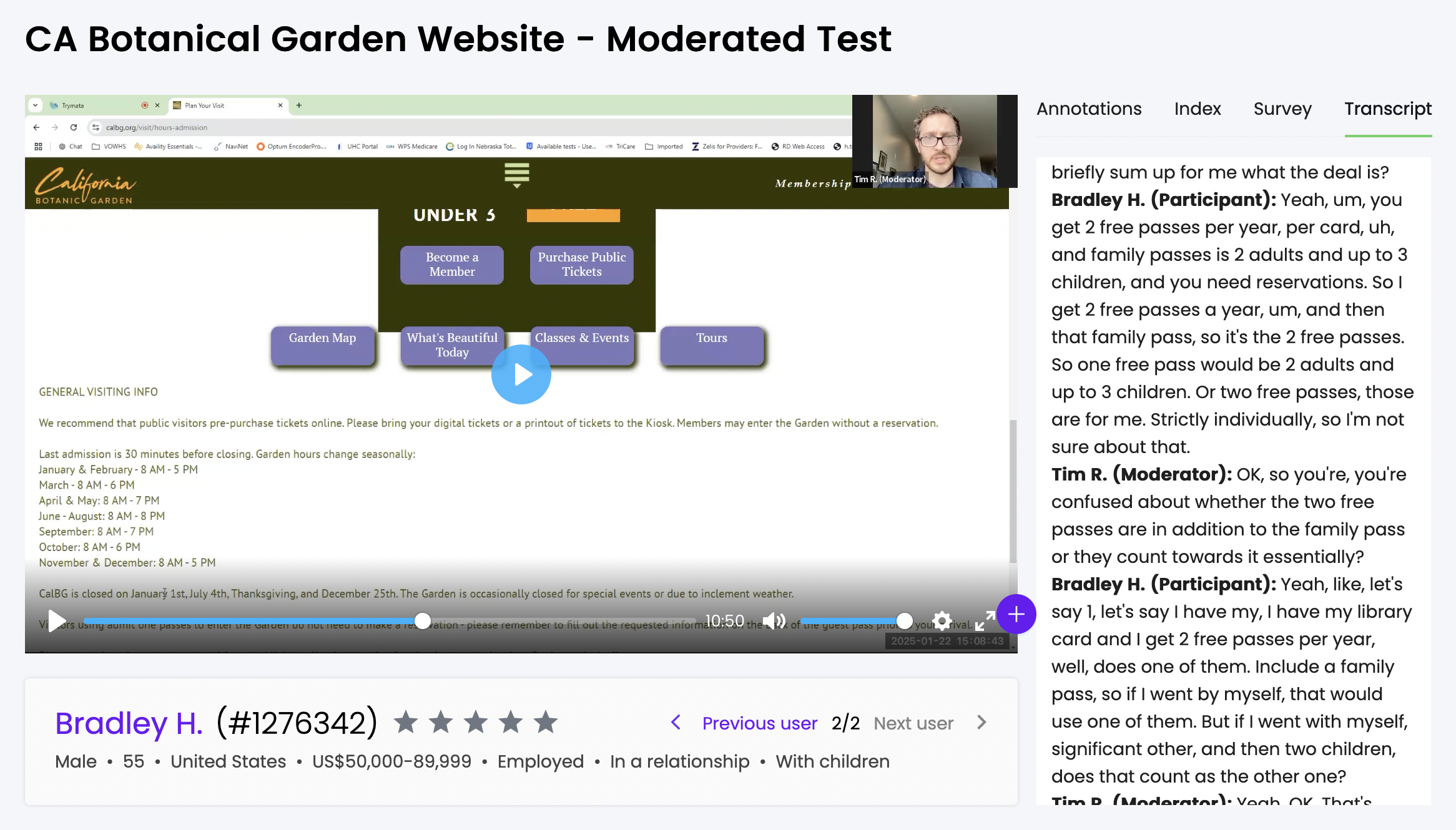
Just in case of a misidentification (or a misclick), you can reset the speaker names at any time from the top of the transcript. This will revert the labels back to the unnamed “Speaker 1” and “Speaker 2,” and allow you to re-assign names from the dropdown once again.
What’s next
These new updates to the moderated testing feature are a helpful quality-of-life improvement to make video review easier. We’re not stopping there, though.
We will be working to ultimately automate the assignment of the speaker names as well, eliminating the need to manually assign them on first viewing. This update will come later in the next few months.
Besides this, we will be continuing to roll out more improvements and expansions to our moderated testing suite, and synchronous research options in general. Stay tuned for more news on these upcoming releases!